

ここはとある大学の研究室。統計学の講義を担当する教授のもとに、学生のマナブくんが質問にやってきました。

(マナブ)この前、60代以上のフリマアプリ利用者の平均資産額が約2500万円で、非利用者より400万円も多かったっていう調査結果をメルカリが発表してましたけど、先生はどう思います?
(教授)この前も教えたように、「平均」は便利な数字だけど注意する必要がある。下の図を使って説明しよう。
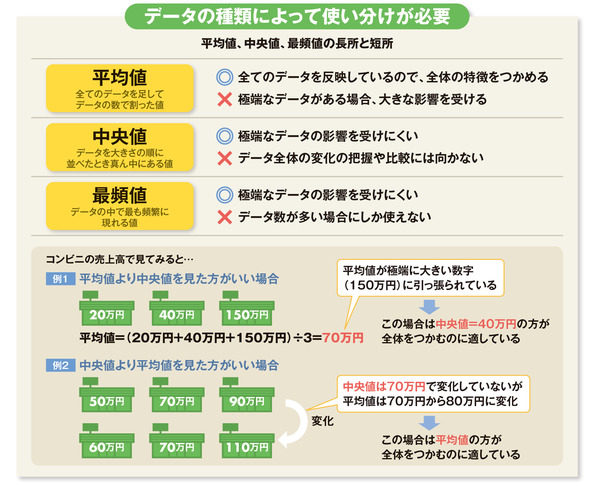
統計学ではデータ全体の特徴や傾向を表す数値を「代表値」と呼ぶ。代表値には三つあって、一番よく使われるのが、全てのデータを足してデータの数で割った「平均値」だね。そのほかに、データを大きさの順に並べたとき真ん中にある値である「中央値」、データの中で最も頻繁に現れる値である「最頻値」があるんだ。
三つの代表値にはそれぞれ、得手不得手があるから、データの種類によって使い分けた方がいい。
まず平均値のいいところは、全てのデータを足して割っているので、全体の特徴をつかみやすいこと。ただ、極端なデータがあるとそれに引っ張られて全体が見えにくくなることもある。
例えばコンビニの売上高で見てみよう(例1)。ある人がコンビニを3店経営していて、1日の売上高がそれぞれ20万円、40万円、150万円だったとする。この場合、3店舗の平均売上高は70万円になるけど、3店舗のうち2店舗は平均の6割以下の売り上げしかない。これじゃ、70万円という数値がデータ全体を代表しているとは言い難いよね。
こんなふうに極端なデータが交じっているときは、平均値よりも中央値を使った方がいいんだ。この場合、中央値は40万円だから、全体をつかむのに適している。
逆に、中央値よりも平均値を使った方がいい場合もある。今度は3店舗の1日の売上高がそれぞれ50万円、70万円、90万円だったとする(例2)。それが60万円、70万円、110万円に変化した場合、中央値はどちらも70万円で変わらない。一方平均値は前者が70万円、後者が80万円に変化している。このように、中央値はデータ全体の変化の観察には向いていないんだ。
(マナブ)なるほど。これまで平均値といえば、全体の真ん中を表すと思ってたけど、そうじゃない場合もあるんですね。
(教授)マナブくんの最初の質問に戻ろうか。フリマアプリ利用者の平均資産額が非利用者より400万円も多かったことをどう思うか。正直なところ中央値などのデータの詳細が公表されていないからなんとも言えないね。でも、「平均」が万能ではないということをいつも念頭に置いて統計を見るようにしたらどうかな。
データリテラシーは"筋トレ"では養えない
マーケティングのための人工知能プログラムの開発に携わるなど、現在最も注目を集めるデータサイエンティストの松本健太郎氏に、データリテラシーの鍛え方を聞いた。
──データリテラシーを鍛えるにはどうすればいいでしょうか。
データリテラシーは、筋トレのように努力すれば養われる類いのものではありません。数字に強くなるというのは、なるべく自分に関係のない情報を削ぎ落とそうとする脳の働きに反するからです。
ではどうすればいいのか。方法は二つあります。
まず、統計の数字がどうやって作られているのかに目を向けること。「政府や企業が作っているんだからちゃんとしてるだろう」ではなく、本当に信頼できるのか疑ってみる。それだけでかなりリテラシーは上がると思います。
民間の統計、例えば需要予測のようなデータは、どうやって作られているのか全く分からない。でも公的統計は作り方や調査票がオープンになっていて全部調べることができます。そういう意味では、初心者が統計データに慣れ親しむためには、公的統計が最も適していると思います。
もう一つの方法は、まずデータに触ってみることです。よくありがちなのが、統計には難しい専門用語が並んでいるので、それを読み解こうとしてどツボにはまること。いちいち言葉の厳密な定義を調べるのではなく、例えば統計上の数字を時系列に並べてみたりすると、上向いているデータが多い中で下落しているデータを見つけたりする。そういう気付きが大事なんです。
──統計を読むとき、どんなことに注意したらいいでしょうか。
データを作る側にも読む側にも必ずバイアス(先入観による偏り)がある。バイアスから抜け出すのは極めて難しいですが、バイアスがかかっている可能性があるんじゃないかと考えることがすごく重要だと思っています。特に、専門家であればあるほどバイアスに陥りやすいので、普通なら気付くはずの目の前の大きな違和感を見逃してしまう。その点、基本的にバイアスがない素人は強い。
──データサイエンティストはどこでも引っ張りだこです。
大企業を含めてほとんどの企業が、データサイエンティストは魔法使いだと思っている。なんかすごいことやってくれるんでしょみたいな。本当に重要なのは、データサイエンティストの言っていることを理解できるリテラシーを持った(データサイエンティスト以外の)人材が社内にいるかどうかなんです。そこに気付いている企業はまだ少ないですね。
難しい数式は一切なし 会話形式の誌上講義ですらすら分かる
『週刊ダイヤモンド』4月13日号の第1特集は「数式なしで学べる! 統計学超入門」です。
今年に入って政府の主要な統計で次々と不正が発覚しました。いずれも、統計学の基礎知識があれば起きるはずのないミスばかりで、各省庁の統計担当者の知識不足や政府の統計軽視の姿勢が浮き彫りになった事件でした。
そこで今回は、政府の不正統計事件を反面教師として、統計学の基本を学ぶための特集を企画しました。
統計学と聞くと、複雑な数式を使いこなさないといけない難しい学問だと思われるかもしれません。安心してください。今回の特集では難しい数式は一切使いません。初心者でも理解できるように専門用語を使わず、教授と学生の会話による誌上講義形式でまとめてあります。
特集では、政府統計で不正が起きた背景や処方箋を提示するとともに、データにだまされないためのリテラシーを鍛える例題をふんだんに用意しました。
さらに、各方面で注目を集めている気鋭のデータサイエンティスト、松本健太郎さんに「特別講義」をお願いしました。1時間目のお題は「フェイスブックはおじさんとおばさんしか使っていない?」、2時間目は「GDPはどこまで正しいのか?」。おもしろそうなテーマだと思いませんか? 松本さんがこのお題にどう答えたのか、ぜひ特集をご覧ください。
もう一つ、今回は特別付録を用意しました。本特集は統計学の「超入門編」ですが、さらに統計学の基礎や応用を学びたい方のために、過去の特集記事から抜粋した基礎編とビジネス応用編をご覧ください。








